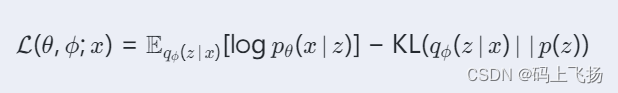1. 为什么需要Batch Normalization
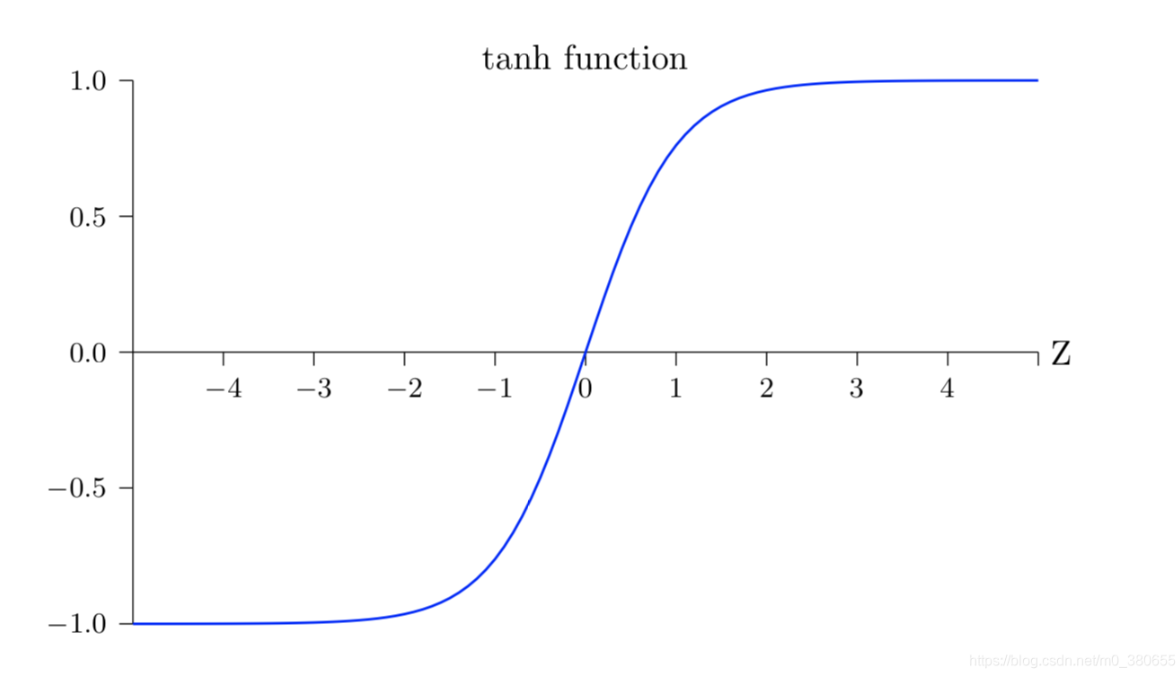
通常我们会在输入层进行数据的标准化处理,这是为了让模型学习到更好的特征。同样,在模型的中间层我们也可以进行normalize。在神经网络中, 数据分布对训练会产生影响。 比如我们使用tanh作为激活函数,当输入激活函数的值很大时,tanh输出值接近饱和如下所示,这样我们再增大x,输出几乎没任何变化,可以理解为模型对数据不再敏感了。这种情况在隐藏层时有发生,因此需要Batch Normalization解决。
2. Batch Normalization层位置
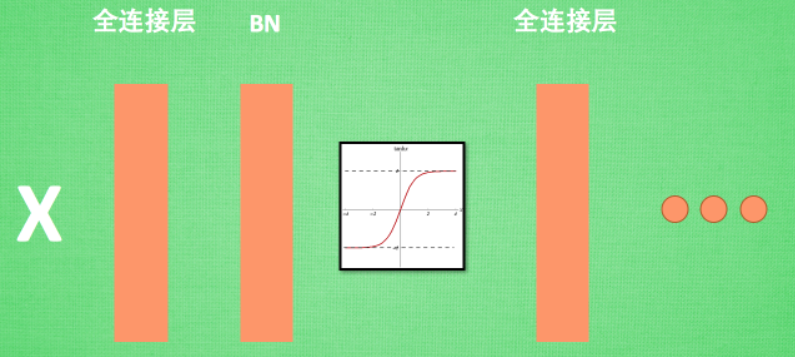
Batch Normalization (BN) 层被添加在每一个全连接和激活函数之间,如下:
3. Batch Normalization作用的形象理解
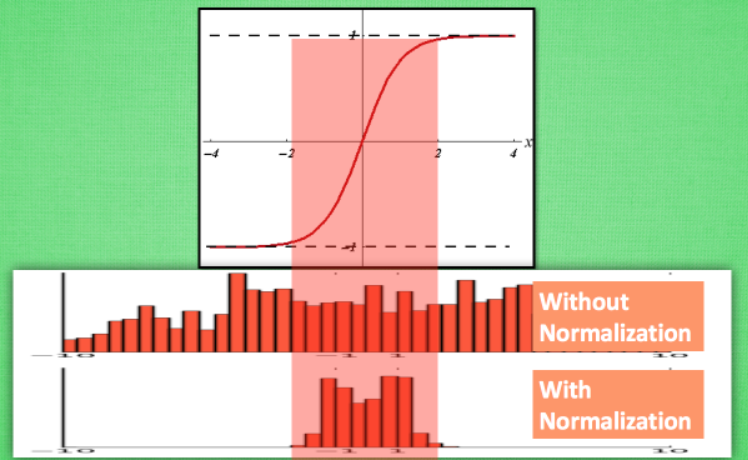
计算结果值的分布对于激活函数很重要。比如还是tanh函数,对于数据值大多分布在中间这个区间的数据, 才能进行更有效的传递。 对比下图这两个在激活之前的值的分布。上者没有进行 normalization, 下者进行了 normalization, 我们通过normalization将数据分布在tanh效果最好的区间内,这样能够更有效地利用 tanh 进行非线性化的过程:
接着,将这两个分布的数据分别通过激活函数,观察输出分布如下图所示。没有 normalize 的数据使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在。再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值:

4. BN算法
我们引入batch normalization的公式。标准化工序就是我们在刚刚一直说的normalization, 但是公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移。原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作。

注:参考https://zhuanlan.zhihu.com/p/24810318